
Introducing Protocol SIFT: Meeting AI Threat Speed with Defensive AI Orchestration
SIFT Protocol is the first autonomous forensic framework to integrate MCP, orchestrating 200+ utilities at machine speed.

It’s 3:14 AM and the terminal is showing red. Error: Invalid profile selected. Profile Win10x64_19041 not found. You’re two hours into a breach investigation, running on caffeine and the vague hope that your manager won’t ask for a status update, and you just burned 20 minutes because you couldn’t remember which Volatility profile matches the memory dump sitting in /mnt/evidence.

The adversary, meanwhile, has already pivoted through three subnets while you were googling syntax. This is what keeps me awake at night.
I’ve been doing this for 27 years. Built SIFT Workstation in 2007 because analysts needed a consistent toolkit instead of hunting down utilities at 2 AM during an active incident. Trained thousands of forensic examiners on these tools. Watched the industry spend billions on detection capabilities while the actual investigation workflow hasn’t fundamentally changed since I was parsing FAT file systems in a windowless SCIF. Defensive OODA loops are measured in hours while offensive loops are now measured in seconds.
Defenders are out here bringing knives to a drone strike.
The GTG-1002 Campaign

In November 2025, Anthropic published something that should have caused more panic than it did: the first documented AI-orchestrated cyber espionage campaign at scale.1 A Chinese state-sponsored group that Anthropic designated GTG-1002 weaponized Claude Code with Model Context Protocol to orchestrate reconnaissance, vulnerability discovery, credential harvesting, and lateral movement across approximately 30 entities including government agencies, tech companies, and financial institutions.
80-90% of tactical operations executed autonomously without human intervention, with human operators only required at 4-6 critical decision points per intrusion.2 The request rates were, in Anthropic’s words, “physically impossible” for humans to match.
The architecture they used, an agentic AI connected to offensive tools via MCP, is the exact same architecture I’d been building for defense.
The fact that Chinese state hackers operationalized this first across 30+ targets with 80-90% autonomy, given the typical velocity of government-sponsored anything, should tell you something about our collective sense of urgency.
The House Homeland Security Committee sent a letter to Anthropic’s CEO requesting testimony within two weeks of the disclosure, because nothing says “we’re taking this seriously” like scheduling a hearing.3 The December 17 hearing happened and the threat actors moved on to their next campaign while we argued about whether AI belongs in security workflows.
Protocol SIFT addresses a specific problem I've watched get worse for two decades: we've trained analysts to be command-line stenographers instead of investigators.
Protocol SIFT Setup and Use
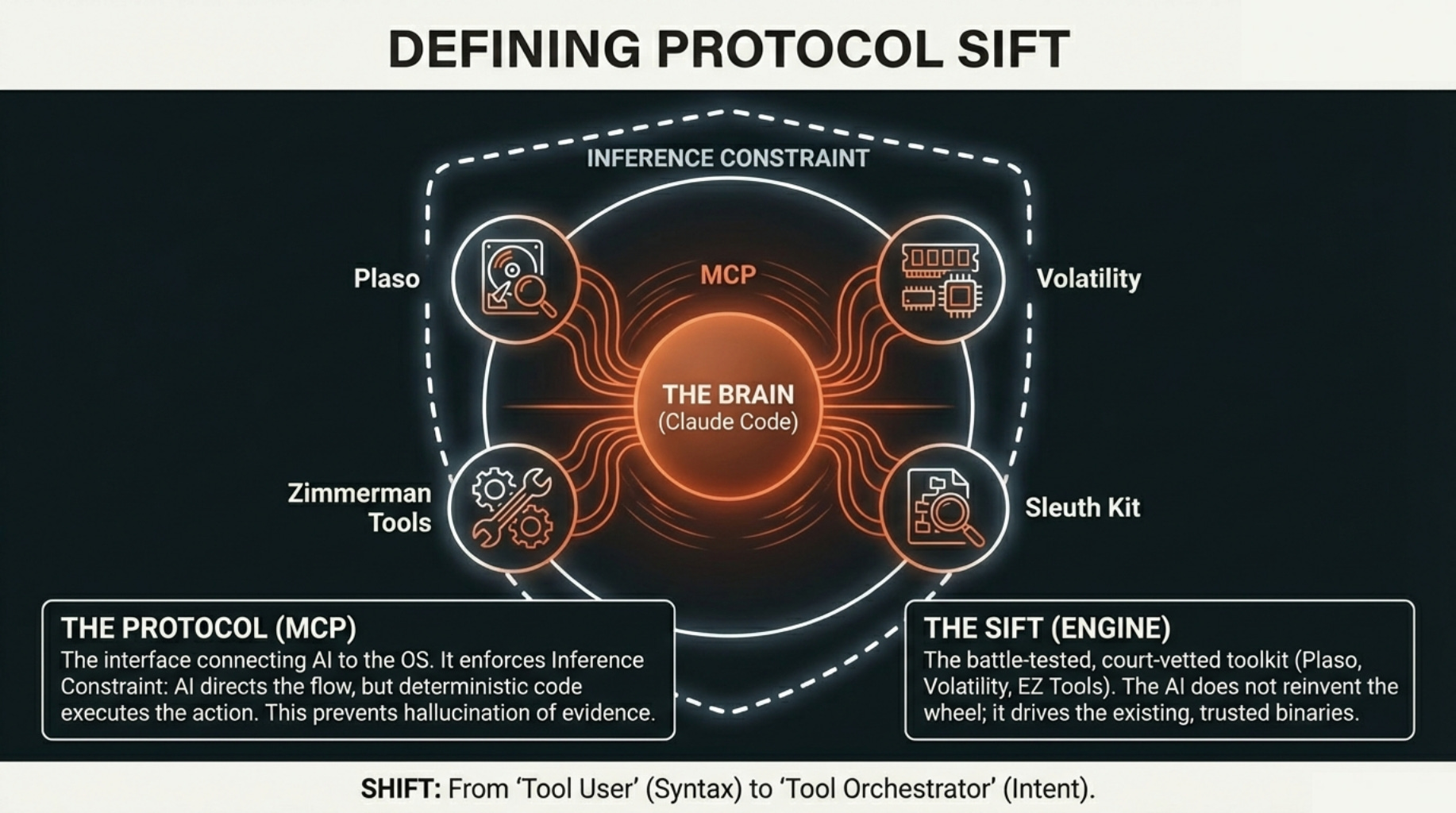
I want to be clear upfront that Protocol SIFT is not a finished product because someone will definitely quote me out of context otherwise. It’s a working integration that I’ve tested with 40+ students across multiple SANS classes.
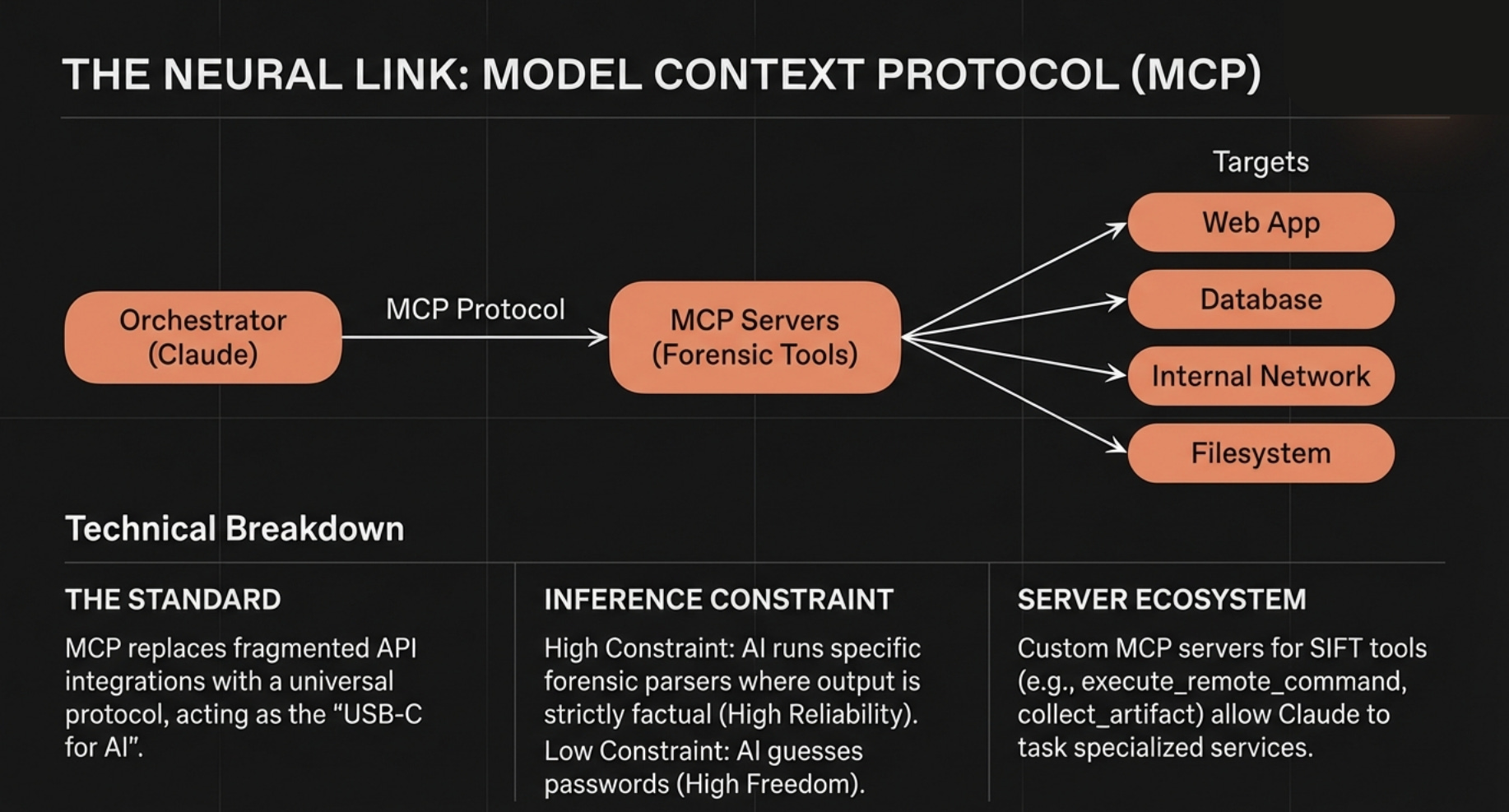
The setup is Claude Code living directly in the SIFT Workstation terminal, connected to 200+ forensic tools via Model Context Protocol.4
MCP is what Anthropic calls “USB-C for AI,” a standardized interface that lets an LLM discover and invoke external tools without custom integration code for every utility.5 Instead of memorizing that the correct invocation for parsing an MFT is dotnet /usr/local/bin/MFTECmd.dll -f /mnt/c/$MFT --csv /cases/output --csvf mft.csv (a string that approximately zero humans can type correctly at 3 AM), the analyst states intent in natural language: “Parse the MFT and find persistence mechanisms established on February 10.”
The system translates intent into precise tool invocations, runs MFTECmd, cross-references with RECmd for registry persistence, correlates timestamps, and reports findings with the actual tool output as evidence.
From “Tool User” to “Tool Orchestrator”
The analyst isn’t replaced, but elevated from syntax memorization to investigative direction. You still need to know what persistence looks like and you still need to understand what questions to ask, but you’re no longer burning cognitive cycles on flag combinations while the adversary automates their entire kill chain and goes to bed.
Hallucinations
The obvious objection is hallucinations. LLMs fabricate things and confidently state facts that don’t exist, and in forensics, fabricated evidence isn’t just unhelpful but potentially career-ending and legally catastrophic. “Your Honor, the AI told me there was malware” is not a defense strategy.
This is where the “Protocol” in Protocol SIFT does real work. We enforce what I call an Inference Constraint layer where the AI directs the workflow.
High constraint means Claude runs strings or binwalk and interprets verified output.
Low constraint, which we explicitly prohibit, would be Claude “summarizing” raw hex directly, and that path leads to the AI claiming to find APT29 indicators in someone’s family photo collection.
Traditional vs AI Workflow

Let me show you what this looks like when it’s not 3 AM and everything’s working, which admittedly is a rare configuration in incident response.
Traditional workflow: An analyst has a memory dump from a suspected compromised workstation. Traditional workflow means running volatility -f image.mem imageinfo to identify the profile, getting it wrong (and you will, eventually, because I’ve done this roughly 10,000 times and still fat-finger profiles), seeing the red error, cursing quietly, trying again, finding the right profile, running pslist, running psscan, and manually comparing outputs looking for discrepancies by scrolling through two terminal windows and hoping you notice the PID that only appears in one. Then you find a suspicious process, run netscan to check for network connections, run malfind to look for injected code, run procdump to extract the binary. Each step requires remembering syntax, interpreting output, deciding the next move.
This is what we’ve been calling “expert analysis” for two decades, and it’s actually just expensive human RAM.
Protocol SIFT workflow: “Scan this memory image for hidden processes and check for C2 connections.” Claude identifies the OS profile automatically, runs pslist and psscan in parallel, spots that PID 2500 appears in psscan but not pslist (classic hidden process indicator), cross-references with netscan and finds an active connection to an external IP, runs malfind on that PID, identifies injected code regions, and dumps the process for static analysis. It outputs a structured report with timestamps, tool outputs, and the reasoning chain. The analyst reviews findings, validates against the raw tool output, makes the call on whether this is malicious. The human is still in the loop, but the loop that used to take 90 minutes now takes 12. The adversary’s loop still runs in seconds, so we haven’t won anything. We’ve just stopped losing quite as badly.
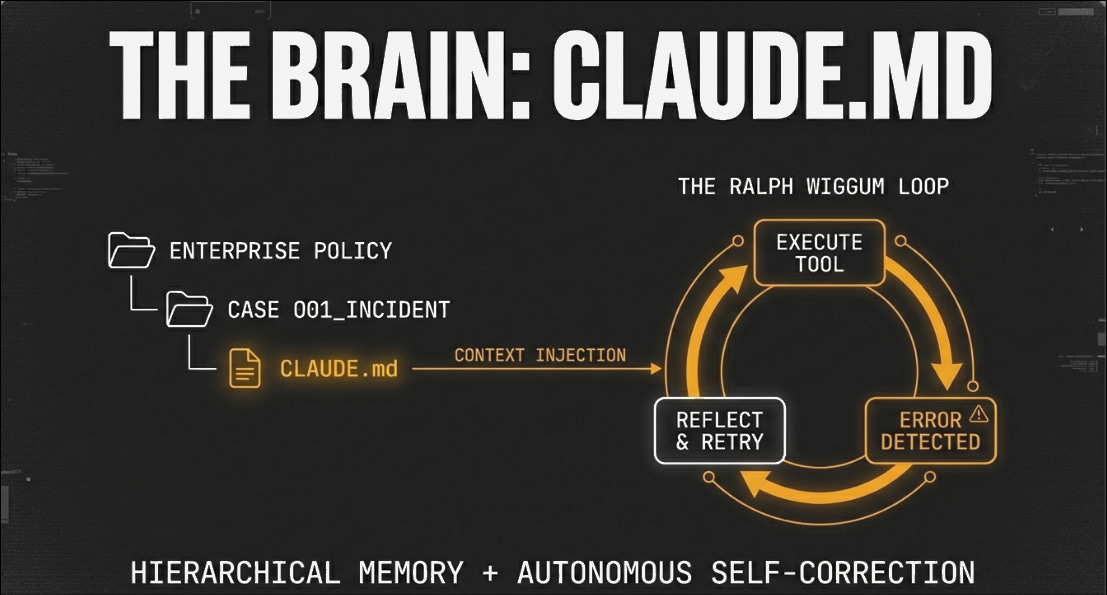
Protocol SIFT implements what I’ve been calling the Ralph Wiggum Loop, a stop hook that intercepts failures before the agent gives up. When a Volatility command returns an error, Claude reads the error message, adjusts its hypothesis (maybe the profile was wrong, maybe the memory image is truncated, maybe Mercury is in retrograde), and retries with a different approach. The loop continues until the task completes or Claude explicitly reports what’s blocking progress and why. This matters more than speed, because a tool that’s fast but fails silently is worse than useless. In forensics you need to know what you couldn’t find as much as what you did find, and the self-correction loop means the system either succeeds or tells you specifically why it couldn’t.
Constraints, Limitations

Hallucination risk: The AI might overstate confidence in findings or claim correlations that don’t hold up under scrutiny, and Anthropic’s own report on GTG-1002 noted their AI sometimes “fabricated credentials” or overstated access levels.6 Our architecture mitigates this by forcing tool verification, but mitigation isn’t elimination. You still need to check the raw output against the AI’s summary, and trust but verify isn’t a platitude here.
Domain gaps: General LLMs struggle with obscure artifact formats like proprietary log structures or unusual file system layouts. Protocol SIFT uses hierarchical CLAUDE.md files to inject forensic protocols and tool documentation, but coverage isn’t complete. When Claude encounters something it doesn’t understand, it sometimes guesses rather than admitting uncertainty, just like humans except Claude doesn’t get defensive when you call it out.
I’ve tested this with 40+ students across multiple classes. Two-thirds showed meaningful improvement in time-to-findings. One-third struggled with the shift in workflow because they’d built 10+ years of muscle memory around specific tool invocations and found it harder to articulate investigative intent than to type commands they’d memorized.
Some people are going to hate this and write angry blog posts about how AI is ruining forensics, and they might not be entirely wrong.
What I don’t know yet is what happens when this scales from classroom pilots to enterprise SOCs running 500 analysts, or what happens when the adversary’s AI and the defender’s AI are both running MCP-based architectures against each other and the whole engagement compresses into minutes, or how we maintain forensic soundness when the verification loop runs faster than human cognition can follow.
Those questions don’t have answers today. Protocol SIFT ships anyway because Chinese state actors aren’t convening working groups to address edge cases before deployment or waiting for peer review.
The velocity gap between AI offense and human defense is already operational, and closing it requires defenders to build with the same architecture (orchestration layer plus tool integration plus autonomous execution) that the adversary has already demonstrated works.
Video Overview or watch here:
Rob T. Lee is Chief AI Officer & Chief of Research, SANS Institute
Anthropic, “Disrupting the first reported AI-orchestrated cyber espionage campaign,” November 13, 2025. https://anthropic.com/news/disrupting-AI-espionage
Per Anthropic disclosure, human operators were required at only 4-6 critical decision points per intrusion. https://anthropic.com/news/disrupting-AI-espionage
House Homeland Security Committee letter to Dario Amodei, November 26, 2025. https://homeland.house.gov/wp-content/uploads/2025/11/2025-11-26-CHS-to-Anthropic-re-Request-to-Testify.pdf Hearing held December 17, 2025. https://homeland.house.gov/hearing/the-quantum-ai-and-cloud-landscape-examining-opportunities-vulnerabilities-and-the-future-of-cybersecurity/
SIFT Workstation: 200+ forensic tools, 125,000+ lifetime downloads. https://sans.org/tools/sift-workstation
Model Context Protocol launched November 25, 2024. Donated to Agentic AI Foundation (Linux Foundation) December 2025. https://modelcontextprotocol.io
Anthropic technical report, Section 4.2: “The AI would sometimes fabricate credentials or overstate findings.” https://assets.anthropic.com/m/ec212e6566a0d47/original/Disrupting-the-first-reported-AI-orchestrated-cyber-espionage-campaign.pdf
is this like SIFT workstation from Sans Institute?
OOMMGG, my name is SIFT. u gotta be kidding me...